トップ>趣味とスポーツ>スポーツ>柔道
裸で儲ける時代TOP>アクセスアップ虎の穴>検索エンジン対策~「検索エンジンの特性」
~検索エンジンの特性~
・サイトがカテゴリ分けされている
|
『ディレクトリ型検索エンジンはサイトが階層状に分類される』
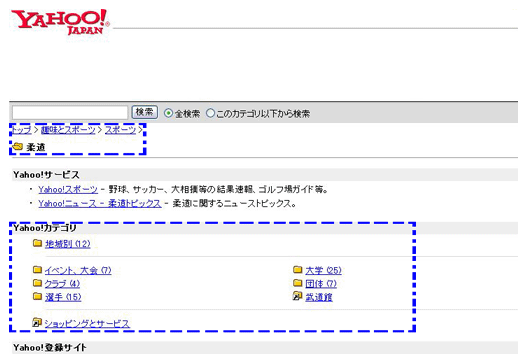
ディレクトリ型検索エンジンの最大の特徴は、ホームページのテーマをカテゴリごとに分類して登録されているとことです。カテゴリは「趣味とスポーツ」→「スポーツ」→「柔道」といったように、大きなカテゴリの中に複数のサブカテゴリが入っています。このように、登録されているサイトは細かくカテゴリに分類され、階層化した形で管理されています。その為、利用者が自分が得たい情報を探す際には、大きなカテゴリから徐々にカテゴリを絞っていき、最終的に表示された候補から、目的のホームページへアクセスすることになります。
| Yahoo!での例: | |
|
|
| ←「トップ」からの階層化 トップ>趣味とスポーツ>スポーツ>柔道 |
|
| ←更に細分化された「サブカテゴリ」 |
またYahoo!を始め多くのディレクトリ型検索エンジンでは、ロボット型の検索エンジンのように、直接単語を入力しての検索も可能です。検索の結果、関連するカテゴリの一覧や登録されたホームページが表示されます。表示されたカテゴリの一覧を調べることで、直接検索結果にはヒットしないが、自分の調べたい情報を含む可能性があるというようなホームページを発見できます。
『ディレクトリ型検索エンジンは人間の「エディタ」が分類している』
各ホームページを正確にカテゴリに分類するのは、プログラムで自動化することが非常に難しい作業です。ページ内の文章や画像を調べ、そこから該当するカテゴリを間違えずに決めるという作業は、高度な判断力が必要な作業だからです。その為、それらのサイトの分類作業は人間が行わなければなりません。
そういった分類作業をする人のことを「エディタ」や「サーファー」などと呼びます。彼らは新しいホームページを登録する際に、実際にサクセスして内容をチェックし、どのカテゴリに分類するかを決定します。また、、そのサイトが登録に適さないと判断すれば、登録を抹消することもあります。
プログラムが片っ端からホームページを登録していくロボット型検索エンジンと比較して、登録ホームページ数は少なくなります。しかしその代わりに、登録されたホームページはエディタのチェックを通っているので、登録ページの質はある程度保証されているようです。
『ディレクトリ型は検索エンジンの元祖』
ディレクトリ型検索エンジンの代表は、なんと言ってもYahoo!です。なにしろYahoo!は、ディレクトリ型検索エンジンの元祖といえる存在だからです。Yahoo!は、当時スタンフォード大学に在学していたデビッド・ファイロとジェリー・ヤンという二人の学生が、自分たち自身の為に作り始めたのがきっかけです。ロボット型の検索エンジンは、ディレクトリ型よりも後に登場するものなので、Yahoo!は全ての検索エンジンの元祖であると言えるでしょう。
またYahoo!以外の現在よく利用されているディレクトリ型検索エンジンには、ボランティアで管理されているOpen
Directoryプロジェクト(DMOZ)があります。
・巡回ロボットが収集したホームページの中から検索を行う
|
『全文検索を可能にするロボット型検索エンジン』
ロボット型検索エンジンとは、インターネット上を巡回する「巡回ロボット」と呼ばれるプログラムを使って自動的にホームページを収集し、その中から検索を行うことができるタイプの検索エンジンです。巡回ロボットは、あるページを収集すると、そのページに含まれる他のページへのリンクをチェックし、リンク先のページを収集し、更にそのページのリンクをチェックして・・・というようにリンクを辿ってデータを収集していきます。
ロボット型検索エンジンの特徴は「指定したキーワードで全文検索を行うことができる」ところです。全文検索とは一般的には「文章全体を対象にした検索」という意味ですが、ここでは「ホームページ全体のどこかに検索したいキーワードが含まれているページを、全て探し出すことができる」ということを意味しています。ロボット型検索エンジンでは、巡回ロボットが収集したデータを単語レベルで分解し、どのページにどんな単語が含まれているか、という情報を全て記録しています。そしてその情報を元に、そのキーワードが含まれるページを全て探し出してくれるのです。
ロボット型の検索エンジンの代表としては、まず何よりも「Google」が挙げられます。「Google」では「Googlebot」という名前のロボットプログラムを使って、ホームページのデータを回収しています。Google以外にも、infoseekやGooなど、全文検索を行うことができる検索エンジンは全てロボット型であると考えて良いでしょう。(ちなみに何年か前ほどまでは「Goo」や「infoseek」などを使うことによりアングラなサイトをヒットさせることができたと思います)
ちなみにロボットは、「クロウラー」「スパイダー」などとも呼ばれています。例えばGoogleでは「クロウラー」と呼んでおり、Googleのホームページで公開されている文書も全て「クロウラー」で統一されています。
『膨大な数のページの中から検索できる』
人間と同じようにリンクを辿っていくといっても、人間と違いロボットは取捨選択を行わず、貼られているリンク全てを総当りで調べていきます。したがってどこからかリンクを貼られているページであれば、必ずページに到着できる可能性があります。意図的に秘密にしているページでなければ、どこからもリンクを貼られていないページというのはあまり考えられないので、ロボットはアクセス可能なホームページのうちのかなりの割合のデータを収集できるわけです。
Googleのトップページには、Googleで検索可能なホームページ、つまりGoogleのロボットが回収したホームページの数が掲載されていますが、2004年7月現在その数は40億を超えており、しかもその値は日に日に増えています。
| Googleでの例: | |
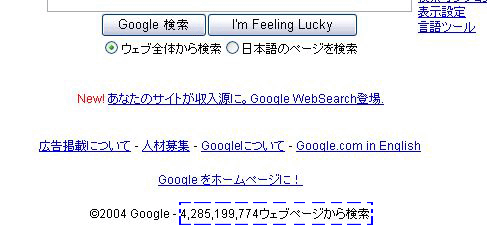 |
←Googleでは、現在登録されているページ数が表示されます。 |
ロボット型検索エンジンを使えば、インターネットで公開されている膨大な数のホームページ(ページ)の中から、自分の求めるキーワードが含まれるページをほぼ全てリストアップすることが可能になっているのです。これが、ロボット型検索エンジンの最大のメリットで、特に「Google」では検索結果表示まで0コンマ何秒という一昔前までは考えれないくらい高速です。
ただし、あまりに多くのホームページが登録されてしまう為、調べたいキーワードが確かに入っているものの、それに関する情報はほとんどないというホームページが検索結果に含まれてしまうこともあります。例えば・・・いい例が私のホームページ「裸で儲ける時代」はアダルト情報は含まれてないにも関わらず「裸」というキーワードでの訪問が多く検索結果の前後はアダルトサイトが多いです。^^;(2004/7/27現在Googleで7位)
『巡回ロボットと更新頻度』
ロボット型検索エンジンの巡回ロボットは、日々インターネット上を巡回し、新しいホームページを登録したり、すでに登録されているホームページの情報を更新しています。しかし、インターネット上には膨大な数のホームページが存在しているので、同じページを頻繁に訪れることは困難です。その為、ホームページを更新しても、すぐに巡回ロボットがきてくれない場合も実情としてあります。そういった場合、検索エンジンが全文検索に利用しているデータ(巡回ロボットが取ってきたデータ)と、実際のホームページ上のコンテンツが異なったものになってしまう為、特定のキーワードでヒットしたホームページに実際訪れてみたら、そのキーワードに関する話題は全然なかったということが起こる可能性もあります
しかし、最近では、検索エンジンも巡回ロボットの巡回頻度を上げたり、頻繁に更新されるページを重点的に巡回するなどして、そういったタイムラグをなるべく少なくする工夫が取られるようになってきており、そういった問題は少なくなりつつあります。
| Googleでの「クローリング」: | |
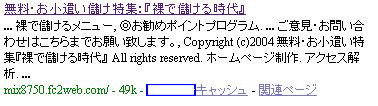 |
←青枠内にクローリングした最新の日付が記載されます |
| 検索エンジンの特性の違いを熟知しておきましょう。それぞれに対応の仕方が違ってきます。 |
裸で儲ける時代TOP>アクセスアップ虎の穴>検索エンジン対策~「検索エンジンの特性」
| SEO | [PR] 爆速!無料ブログ 無料ホームページ開設 無料ライブ放送 | ||
